Hola amigos de blogofsysadmins aqui les dejo otro script en bash que uso para hacer backup de mis bases de datos Mysql en un servidor FreeNas via SMB (Samba), son bastante útiles si se ponen en un cron job y automaticamente hacer los respaldos por las noches o cuando querais¡¡
Cada uno ya que personalice el script base a sus necesidades
#!/bin/bash
Backup_dir_temp="/shellscripts/temp"
Work_dir="/shellscripts/workdir"
Mount_dir="//192.168.0.xxx/Backups/Web_Databases"
Backup_files="*.sql"
Days=7
Day=$(date +%F)
#Respaldamos nuestrass bases de datos(cabia los datos tus datos)
cd $Backup_dir_temp
mysqldump -uroot -pPassword Database_1 > Database_1_$Day.sql
mysqldump -uroot -pPassword Database_2 > Database_2_$Day.sql
mysqldump -uroot -pPassword Database_3 > Database_3_$Day.sql
mysqldump -uroot -pPassword Database_4 > Database_4_$Day.sql
mysqldump -uroot -pPassword Database_5 > Database_5_$Day.sql
Archive_file="Databases_Backup_$Day.zip"
#montamos Mount_dir via samba en Backup_dir
mount -t cifs //192.168.0.xx1/Backups/Web_Databases $Work_dir -o username=myUserName,password=myPassword
#Eliminanos el archivo mas viejo si ya se cumplieron "$Days" dias
# Contamos el numero de archivos que hay en el directorio de respaldo
file_count=`ls $Work_dir | wc -l`
# Comparamos si hay mas de $days archivos para borrar el mas viejo
if [ $file_count = $Days ]
then
cd "$Work_dir" && ls -tr | head -n 1 | xargs rm -f
echo "Removiendo el archivo mas viejo..."
else
echo ""
fi
#Creamos el archivo comprimido con todos los archivos sql
zip -r "$Work_dir"/$Archive_file $Backup_files
#Borramos el directorio temporal
rm -rf $Backup_dir_temp/*.*
#Desmontamos el directorio SMB
umount $Work_dir
Hasta el momento la forma mas fácil de compartir archivos en Internet con todo el mundo es usando algún servicio de compartición o sincronización de archivos, tales como Ubuntu One, Dropbox, Wingedbox, etc.
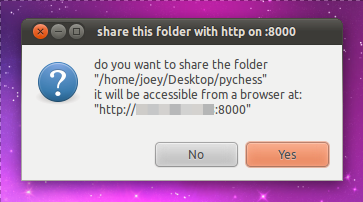
Pero el usuario de Gnome-Look hardball ha subido a Gnome-Look un script que hace lo mismo que cualquiera de estos servicios pero directamente desde tu equipo y en unos cuantos segundos, permitiéndote compartir todo lo que quieras con el que quieras por el puerto :8000 de tu equipo. El script te permite incluso compartir directorios montados con gvfs, como los directorios de Windows, y lo única dependencia que necesita para funcionar es Zenity.
Otro punto a favor de este script seria el mantener todos tus datos dentro de tu propio equipo, mas que nada en estos días donde la privacidad cumple un papel tan importante y donde incluso el concepto de los servicios en la nube se pone a prueba por el lanzamiento de Google Chrome OS.
Ahora para instalar el script solo debes descargarlo desde Gnome-Look – share-http-here, darle permisos de ejecución, copiarlo al directorio ~/.gnome2/nautilus-scripts/ y reiniciar Nautilus para poder acceder a este desde el menú contextual Scripts del directorio que desees compartir.
También puedes ejecutar los siguientes comandos en la terminal para instalarlo de forma mas sencilla:
Nota: es posible que tengas que modificar el script en caso de tener conexión por medio de WiFi en lugar de cableada. Para esto solo tienes que reemplazar eth0 por wlan0 dentro del script.
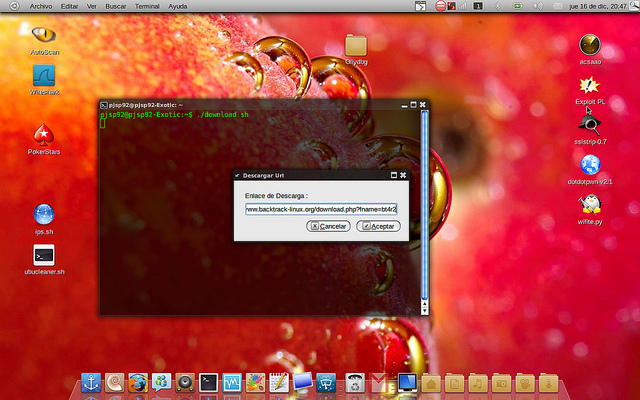
Un muy útil código que podemos utilizar en nuestros scripts cuando queremos descargar un fichero y mostrar una barra de progreso del mismo (requiere zenity instalado en la máquina).
Este es el Script Original en Ingles, Abajo os pondré el mio que modifique básicamente lo puse en español
DOWNLOAD() {
rand="$RANDOM `date`"
pipe="/tmp/pipe.`echo '$rand' | md5sum | tr -d ' -'`"
mkfifo $pipe
wget -c $1 2>&1 | while read data;do
if [ "`echo $data | grep '^Length:'`" ]; then
total_size=`echo $data | grep "^Length:" | sed 's/.*\((.*)\).*/\1/' | tr -d '()'`
fi
if [ "`echo $data | grep '[0-9]*%' `" ];then
percent=`echo $data | grep -o "[0-9]*%" | tr -d '%'`
current=`echo $data | grep "[0-9]*%" | sed 's/\([0-9BKMG.]\+\).*/\1/' `
speed=`echo $data | grep "[0-9]*%" | sed 's/.*\(% [0-9BKMG.]\+\).*/\1/' | tr -d ' %'`
remain=`echo $data | grep -o "[0-9A-Za-z]*$" `
echo $percent
echo "#Downloading $1\n$current of $total_size ($percent%)\nSpeed : $speed/Sec\nEstimated time : $remain"
fi
done > $pipe &
wget_info=`ps ax |grep "wget.*$1" |awk '{print $1"|"$2}'`
wget_pid=`echo $wget_info|cut -d'|' -f1 `
zenity --progress --auto-close --text="Connecting to $1\n\n\n" --width="350" --title="Downloading"< $pipe
if [ "`ps -A |grep "$wget_pid"`" ];then
kill $wget_pid
fi
rm -f $pipe
}
if [ $1 ];then
DOWNLOAD "$1"
else
dllink=$(zenity --entry --text "Your download link :" --width="350" --entry-text "" --title="Download url")
if [ $dllink ];then
DOWNLOAD "$dllink"
fi
fi
lo Guardamos como download.sh le damos permisos con chmod +x download.sh & Lo ejecutamos ./download.sh
Script para traducir textos desde linea de comandos Un script muy sencillo que nos permitira si queremos utilizar traducción instantaneo en nuestros pequeños programas de bash. Basicamente se hace uso de Google Translate Ajax API y de “curl” para hacer una petición HTTP con los parametros adecuados y se analiza la respuesta recibida, los parametros son el idioma “origen”, el idioma “destino” y el string que queremos traducir.
#!/usr/bin/env bash
# gtranslate.sh
# Translate using Google Translate Ajax API:
# http://ajax.googleapis.com/ajax/services/language/translate?v=1.0 \
# &langpair=en|es&q=hello+world
# More Info: http://code.google.com/apis/ajaxlanguage/documentation/
# ksaver (at identi.ca), March 2010.
# Licence: Public Domain Code.
progname=$(basename $0)
if [ -z "$3" ]
then
echo -e "Usage: $progname lang1 lang2 'string of words to translate...'"
echo -e "Example: $progname en es 'Hello World!'\n"
exit
fi
FROM="$1"
TO="$2"
# Google Translate Ajax API Url
TRANSURL='http://ajax.googleapis.com/ajax/services/language/translate?v=1.0'
LANGPAIR="$FROM|$TO"
shift 2
# Parse string to translate, change ' ' to '+'
# STRING: String to translate.
STRING="$@"
PSTRING=$(echo "$STRING" |tr ' ' '+')
# Get translation
RESPONSE=$(/usr/bin/env curl -s -A Mozilla \
$TRANSURL'&langpair='$LANGPAIR'&q='$PSTRING)
echo -n "$progname> "
# Parse and clean response, to show only translation.
echo "$RESPONSE" |cut -d ':' -f 3 |cut -d '}' -f 1
Para muchos de nosotros Gedit no es más que un editor de textos, reemplazo del clásico bloc de notas de Windows, en el que podemos modificar pequeños y simples (al carecer de formato) ficheros de texto como ficheros de configuración y/o propiedades.
Aunque mi entorno de desarrollo (IDE) suele ser Eclipse, de un tiempo a esta parte vengo utilizándolo muy a menudo para la creación y edición de scripts tanto en Bash como en Groovy (lenguaje que, por necesidades del cliente, me he visto “obligado” a aprender).
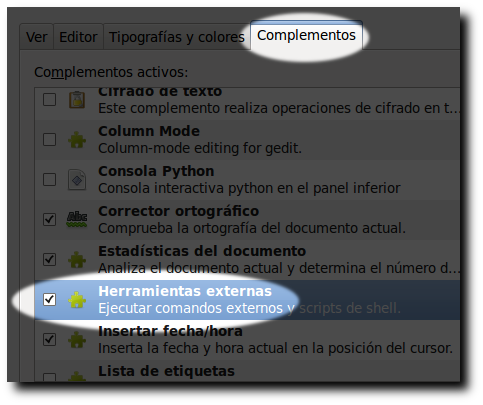
Cansado de la rutina de editar el fichero con GEdit (o vim si se terciaba), y tener abierta una terminal para probar lo que iba modificando me dio por investigar qué otras alternativas existen para ello descubriendo la potencia y flexibilidad del complemento Herramientas externas.
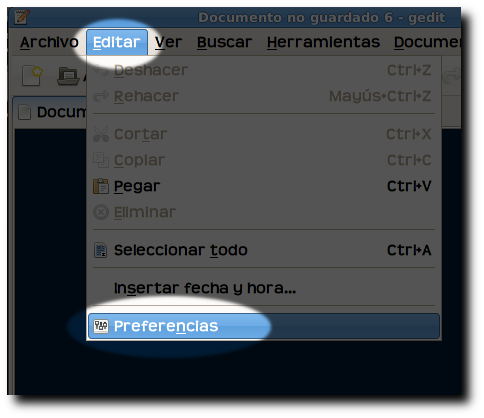
Activando el complemento
Tan sencillo como buscarlo en las preferencias de GEdit
y marcar la casilla correspondiente
para finalizar no queda más que configurarlo
Definiendo el primer script
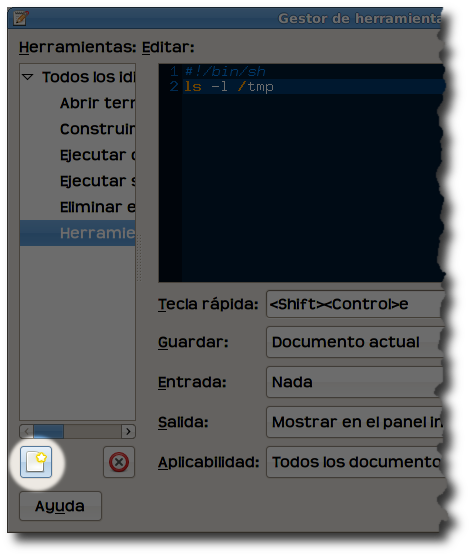
Como introducción y, a modo de ejemplo, nos limitaremos a mostrar en consola el resultado de listar el contenido del directorio temporal del sistema (/tmp) para lo cual añadiremos un nuevo comando pulsando el botón existente para ello
y escribiremos el siguiente código en la zona de edición habilitada
ls -l /tmp
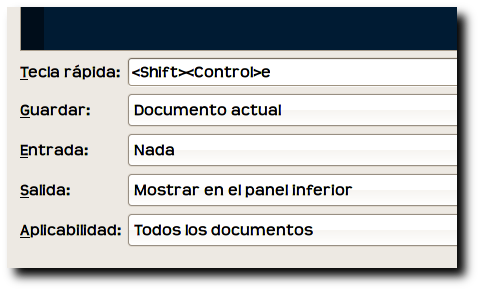
A modo de referencia podéis ver cómo he definido el resto de parámetros del script en la siguiente captura
destacando entre ellos
Tecla rápida para lanzar el script cuando estemos editando en GEdit sin tener que buscar el script en los menús de la aplicación
Guardar: Documento actual para evitarnos tener que preocuparnos de guardar el documento antes de lanzar el script. Con el valor Documento actual se guardará el fichero que estemos editando de modo que lo que se ejecute sea exactamente lo último que hemos escrito evitando de este modo falsos resultados (imagina que haces algunos cambios y ejecutas el script: se ejecutaría sobre lo último que tienes en disco que no coincide en absoluto con lo que estás viendo en pantalla)
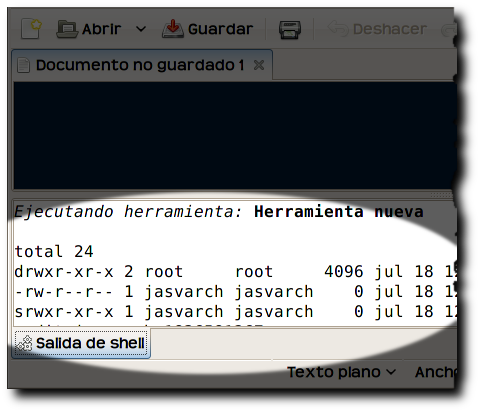
Ejecutando scripts
Tan sencillo como pulsar la combinación de teclas definida en el paso anterior (CTRL+SHIFT+E en la configuración de referencia) y observar el resultado en el panel inferior del editor
NOTA: Curiosamente, si estás editando un documento nuevo que no ha sido guardado nunca en disco, el complemento se limita a pedirte dónde guardarlo y no ejecuta el script . En dicho caso dale un nombre y vuelve a lanzarlo pulsando nuevamente la combinación de teclas asociada.
El script definitivo
Una vez que hemos aprendido cómo funciona el complemento con un ejemplo sencillo (listar el contenido del directorio /tmp) pasemos a la finalidad de este artículo: ejecutar el contenido del script que estamos editando.
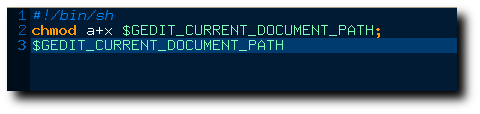
No tenemos más que cambiar el código del script anterior por éste:
GEdit es, en apariencia, un sencillo editor de textos que consume muy pocos recursos y que está llamado a convertirse en el equivalente a editores de textos como el UltraEdit de Windows (que al escribir este artículo acabo de descubrir que ya existe versión para Linux :O aunque, como era de esperar, no es Software libre )
Bonus tip
Para aquellos que les haya llamada la posibilidad de ejecutar scripts desde Gedit les recomiendo que le echen un vistazo a la colección de ejemplos de scripts que existe pues es mucho lo que se puede aprender de ellos.